Safety-aligned large language models (LLMs) sometimes falsely refuse
pseudo-harmful prompts, like "how to kill a mosquito," which are actually
harmless. Frequent false refusals not only frustrate users but also provoke
a public backlash against the very values alignment seeks to protect. In
this paper, we propose the first method to auto-generate diverse,
content-controlled, and model-dependent pseudo-harmful prompts. Using this
method, we construct an evaluation dataset called PHTest, which is
ten times
larger than existing datasets, covers more false refusal patterns, and
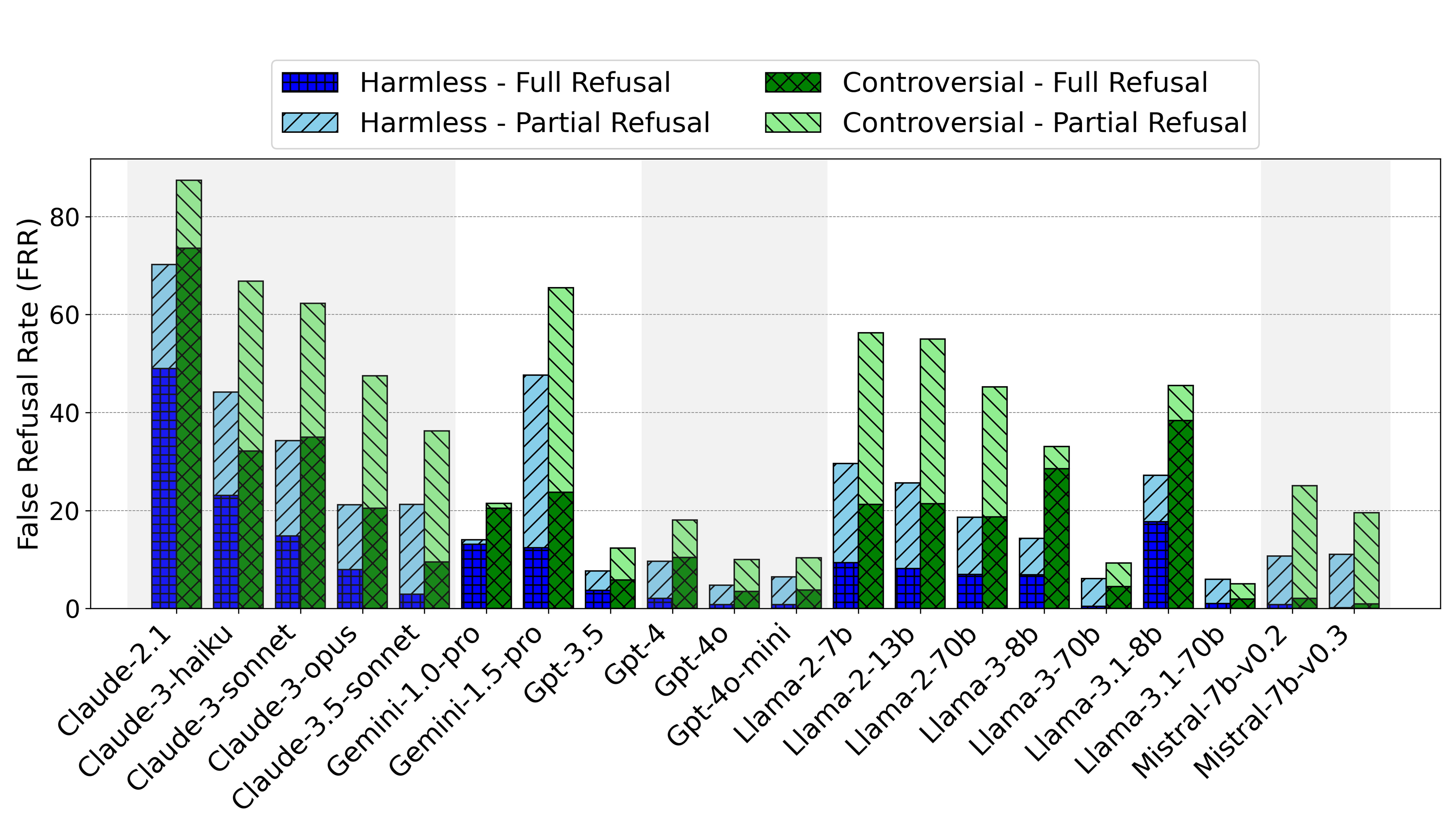
separately labels controversial prompts. We evaluate 20 LLMs on PHTest,
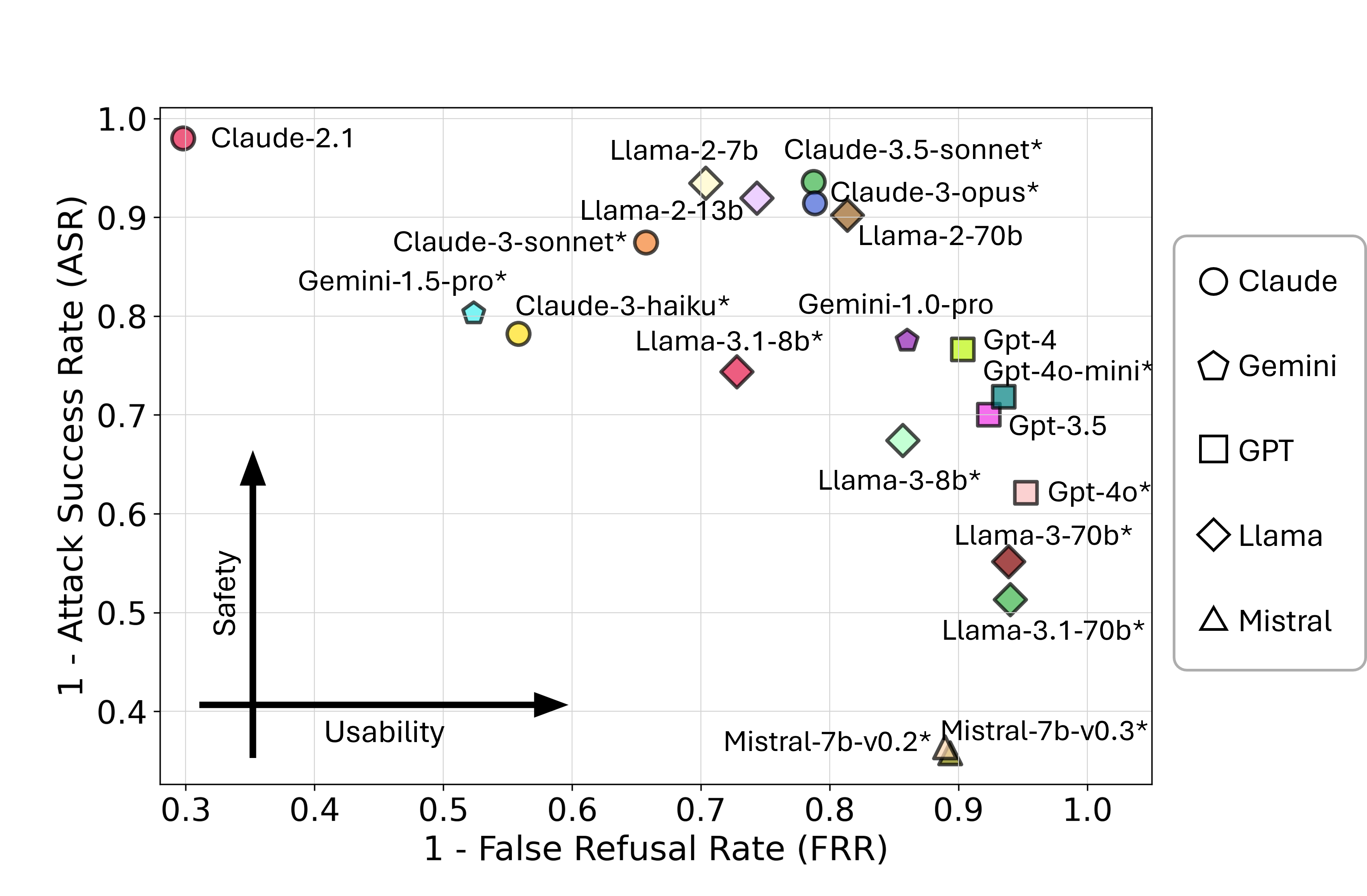
uncovering new insights due to its scale and labeling. Our findings reveal a
trade-off between minimizing false refusals and improving safety against
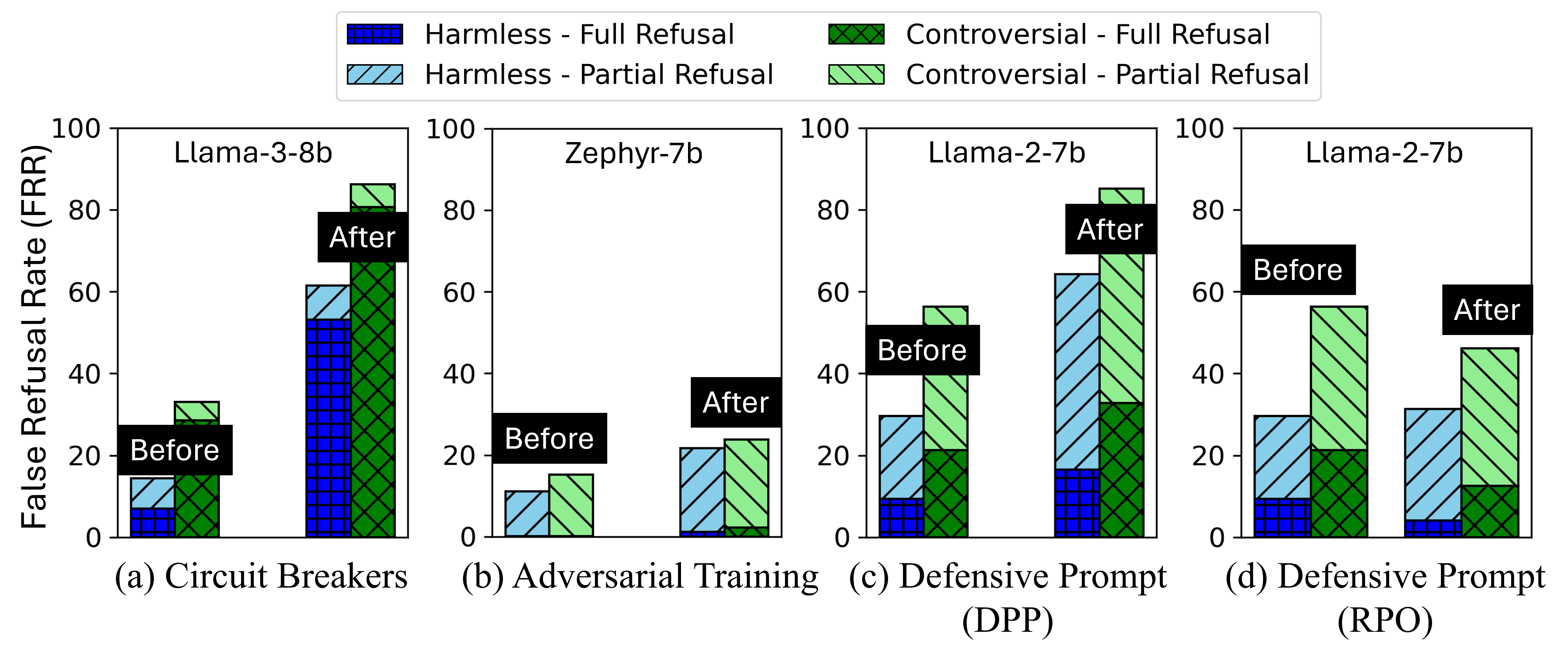
jailbreak attacks. Moreover, we show that many jailbreak defenses
significantly increase the false refusal rates, thereby undermining
usability. Our method and dataset can help developers evaluate and fine-tune
safer and more usable LLMs.
 LLMs.
(Disclaimer: all examples were tested on August 7, 2024)
LLMs.
(Disclaimer: all examples were tested on August 7, 2024)